Q-learning algorithm on mock data set¶
Overview¶
In the previous example, we applied Q-learning on a dataset consisting of three columns. Moreover, we used a one dimensional state space; we discretized the range \([0,1]\) into bins and used the resulting bin index as the state index. In this example, we will simply allow for more columns in the data set. Other than that, this example is the same as the previous one.
Code¶
The necessary imports
import random
import numpy as np
from src.examples.helpers.load_full_mock_dataset import load_discrete_env, get_ethinicity_hierarchy, \
get_gender_hierarchy, get_salary_bins, load_mock_subjects
from src.datasets import ColumnType
from src.spaces.env_type import DiscreteEnvType
from src.spaces.action_space import ActionSpace
from src.spaces.actions import ActionIdentity, ActionStringGeneralize, ActionNumericBinGeneralize
from src.algorithms.q_learning import QLearnConfig, QLearning
from src.policies.epsilon_greedy_policy import EpsilonGreedyPolicy, EpsilonDecayOption
from src.trainers.trainer import Trainer, TrainerConfig
from src.examples.helpers.plot_utils import plot_running_avg
from src.utils import INFO
Next establish a set of configuration parameters
# configuration params
N_STATES = 10
GAMMA = 0.99
ALPHA = 0.1
PUNISH_FACTOR = 2.0
MAX_DISTORTION = 0.7
MIN_DISTORTION = 0.4
SAVE_DISTORTED_SETS_DIR = "/home/alex/qi3/drl_anonymity/src/examples/q_learning_all_cols_results/distorted_set"
EPS = 1.0
EPSILON_DECAY_OPTION = EpsilonDecayOption.CONSTANT_RATE # .INVERSE_STEP
EPSILON_DECAY_FACTOR = 0.01
USE_IDENTIFYING_COLUMNS_DIST = True
IDENTIFY_COLUMN_DIST_FACTOR = 0.1
N_EPISODES = 1001
N_ITRS_PER_EPISODE = 30
OUT_OF_MAX_BOUND_REWARD = -1.0
OUT_OF_MIN_BOUND_REWARD = -1.0
IN_BOUNDS_REWARD = 5.0
OUTPUT_MSG_FREQUENCY = 100
N_ROUNDS_BELOW_MIN_DISTORTION = 10
The dirver code brings all the elements together
if __name__ == '__main__':
# set the seed for random engine
random.seed(42)
# specify the column types. An identifying column
# will me removed from the anonymized data set
# An INSENSITIVE_ATTRIBUTE remains intact.
# A QUASI_IDENTIFYING_ATTRIBUTE is used in the anonymization
# A SENSITIVE_ATTRIBUTE currently remains intact
column_types = {"NHSno": ColumnType.IDENTIFYING_ATTRIBUTE,
"given_name": ColumnType.IDENTIFYING_ATTRIBUTE,
"surname": ColumnType.IDENTIFYING_ATTRIBUTE,
"gender": ColumnType.QUASI_IDENTIFYING_ATTRIBUTE,
"dob": ColumnType.SENSITIVE_ATTRIBUTE,
"ethnicity": ColumnType.QUASI_IDENTIFYING_ATTRIBUTE,
"education": ColumnType.SENSITIVE_ATTRIBUTE,
"salary": ColumnType.QUASI_IDENTIFYING_ATTRIBUTE,
"mutation_status": ColumnType.SENSITIVE_ATTRIBUTE,
"preventative_treatment": ColumnType.SENSITIVE_ATTRIBUTE,
"diagnosis": ColumnType.INSENSITIVE_ATTRIBUTE}
# define the action space
action_space = ActionSpace(n=10)
# all the columns that are SENSITIVE_ATTRIBUTE will be kept as they are
# because currently we have no model
# also INSENSITIVE_ATTRIBUTE will be kept as is
# in order to declare this we use an ActionIdentity
action_space.add_many(ActionIdentity(column_name="dob"),
ActionIdentity(column_name="education"),
ActionIdentity(column_name="salary"),
ActionIdentity(column_name="diagnosis"),
ActionIdentity(column_name="mutation_status"),
ActionIdentity(column_name="preventative_treatment"),
ActionIdentity(column_name="ethnicity"),
ActionStringGeneralize(column_name="ethnicity",
generalization_table=get_ethinicity_hierarchy()),
ActionStringGeneralize(column_name="gender",
generalization_table=get_gender_hierarchy()),
ActionNumericBinGeneralize(column_name="salary",
generalization_table=get_salary_bins(ds=load_mock_subjects(),
n_states=N_STATES))
)
action_space.shuffle()
env = load_discrete_env(env_type=DiscreteEnvType.TOTAL_DISTORTION_STATE,
n_states=N_STATES,
min_distortion=MIN_DISTORTION, max_distortion=MAX_DISTORTION,
total_min_distortion=MIN_DISTORTION, total_max_distortion=MAX_DISTORTION,
out_of_max_bound_reward=OUT_OF_MAX_BOUND_REWARD,
out_of_min_bound_reward=OUT_OF_MIN_BOUND_REWARD,
in_bounds_reward=IN_BOUNDS_REWARD,
punish_factor=PUNISH_FACTOR,
column_types=column_types,
action_space=action_space,
save_distoreted_sets_dir=SAVE_DISTORTED_SETS_DIR,
use_identifying_column_dist_in_total_dist=USE_IDENTIFYING_COLUMNS_DIST,
use_identifying_column_dist_factor=IDENTIFY_COLUMN_DIST_FACTOR,
gamma=GAMMA,
n_rounds_below_min_distortion=N_ROUNDS_BELOW_MIN_DISTORTION)
agent_config = QLearnConfig(n_itrs_per_episode=N_ITRS_PER_EPISODE, gamma=GAMMA,
alpha=ALPHA,
policy=EpsilonGreedyPolicy(eps=EPS, n_actions=env.n_actions,
decay_op=EPSILON_DECAY_OPTION,
epsilon_decay_factor=EPSILON_DECAY_FACTOR))
agent = QLearning(algo_config=agent_config)
trainer_config = TrainerConfig(n_episodes=N_EPISODES, output_msg_frequency=OUTPUT_MSG_FREQUENCY)
trainer = Trainer(env=env, agent=agent, configuration=trainer_config)
trainer.train()
avg_rewards = trainer.total_rewards
plot_running_avg(avg_rewards, steps=100,
xlabel="Episodes", ylabel="Reward",
title="Running reward average over 100 episodes")
avg_episode_dist = np.array(trainer.total_distortions)
print("{0} Max/Min distortion {1}/{2}".format(INFO, np.max(avg_episode_dist), np.min(avg_episode_dist)))
plot_running_avg(avg_episode_dist, steps=100,
xlabel="Episodes", ylabel="Distortion",
title="Running distortion average over 100 episodes")
Results¶
The following images show the performance of the learning process
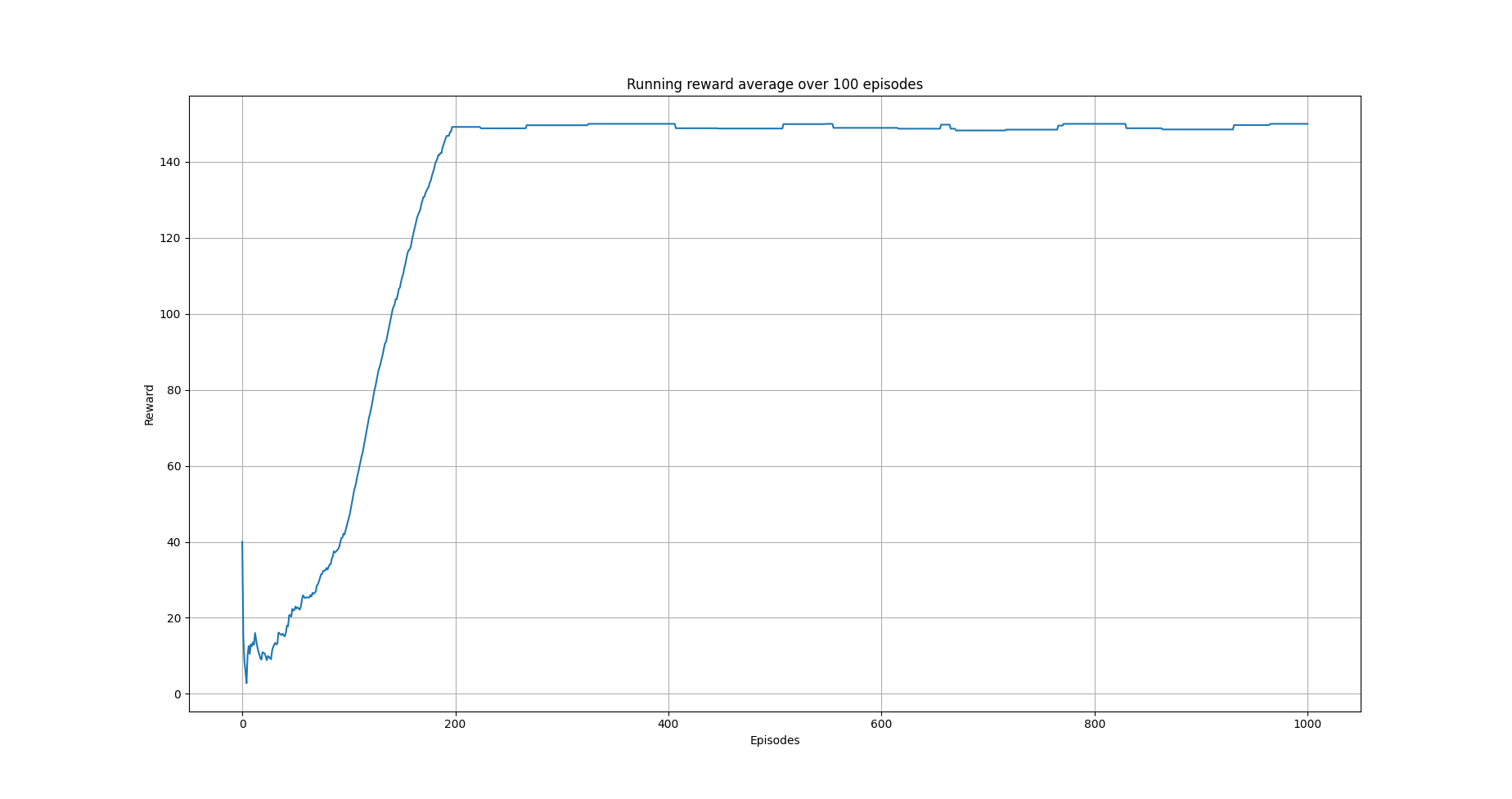
Running average reward.¶
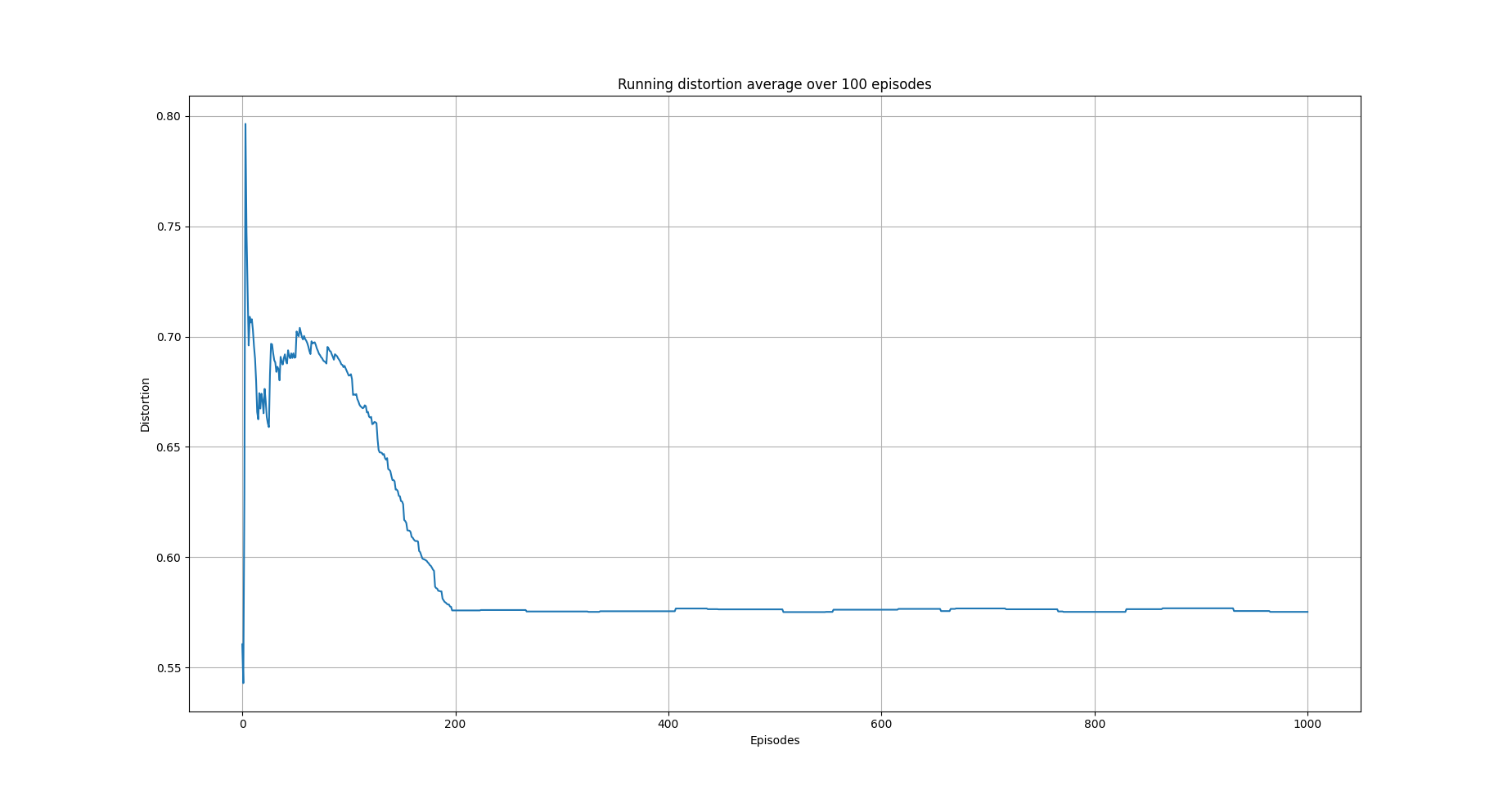
Running average total distortion.¶
References¶
Richard S. Sutton and Andrw G. Barto, Reinforcement Learning. An Introduction 2nd Edition, MIT Press.