Conceptual overview¶
The term data anonymization refers to techiniques that can be applied on a given dataset, \(D\), such that it makes it difficult for a third party to identify or infer the existence of specific individuals in \(D\). Anonymization techniques, typically result into some sort of distortion of the original dataset. This means that in order to maintain some utility of the transformed dataset, the transofrmations applied should be constrained in some sense. In the end, it can be argued, that data anonymization is an optimization problem meaning striking the right balance between data utility and privacy.
Reinforcement learning is a learning framework based on accumulated experience. In this paradigm, an agent is learning by iteracting with an environment without (to a large extent) any supervision. The following image describes, schematically, the reinforcement learning framework .
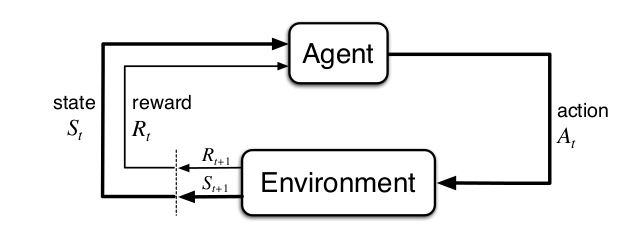
Reinforcement learning paradigm.¶
The agent chooses an action, \(A_t \in \mathbb{A}\), to perform out of predefined set of actions \(\mathbb{A}\). The chosen action is executed by the environment instance and returns to the agent a reward signal, \(R_{t+1}\), as well as the new state, \(S_{t + 1}\), that the enviroment is in. The overall goal of the agent is to maximize the expected total reward i.e.
The framework has successfully been used to many recent advances in control, robotics, games and elsewhere.
In this work we are intersted in applying reinforcment learning techniques, in order to train agents to optimally anonymize a given data set. In particular, we want to consider the following two scenarios
A tabular data set is to be publicly released
A data set is behind a restrictive API that allows users to perform certain queries on the hidden data set.
For the first scenario, let’s assume that we have in our disposal two numbers \(DIST_{min}\) and \(DIST_{max}\). The former indicates the minimum total data set distortion that it should be applied in order to satisfy some minimum safety criteria. The latter indicates the maximum total data set distortion that it should be applied in order to satisfy some utility criteria. Note that the same idea can be applied to enforce constraints on how much a column should be distorted. Furtheremore, let’s assume the most common transformations applied for data anonymization
Generalization
Suppresion
Permutation
Pertubation
Anatomization
We can conceive the above transformations as our action set \(\mathbb{A}\). We can now cast the data anonymity problem into a form suitable for reinforcement learning. Specifically, our goal, and the agent’s goal in that matter, is to obtain a policy $pi$ of transformations such that by following $pi$, the data set total distortion will be into the interval \([DIST_{min}, DIST_{max}]\). This is done by choosing actions/transformations from \(\mathbb{A}\). This is shown schematically in the figure below
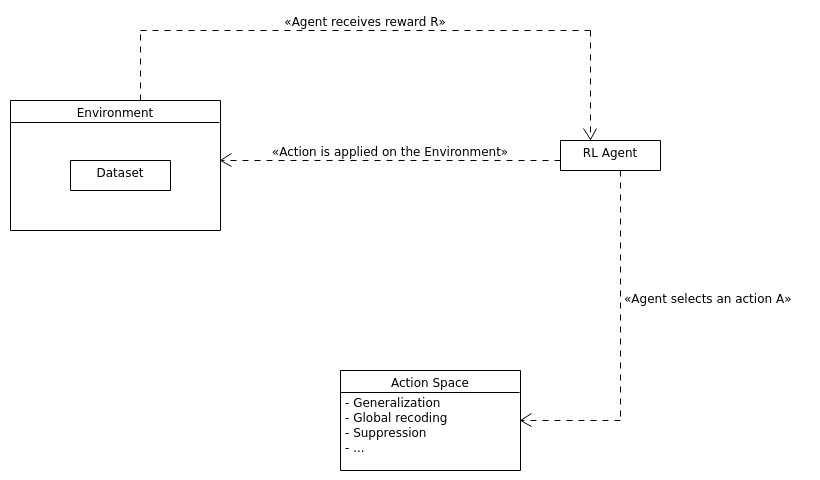
Data anonymization using reinforcement learning.¶
Thus the environment is our case is an entity that encapsulates the original data set and controls the actions applied on it as well as the reward signal \(R_{t+1}\) and the next state \(S_{t+1}\) to be presented to the agent.
Nevertheless, there are some caveats that we need to take into account. We summarize these below.
First, we need a reward policy. The way we assign rewards implicitly specifies the degree of supervision we allow. For instance we could allow for a reward to be assigned every time a transformation is applied. This strategy allows for faster learning but it leaves little room for the agent to come up with novel strategies. In contrast, returning a reward at the end of the episode, although it increases the training time, it allows the agent to explore novel strategies. Related to the reward assignement is also the follwing issue. We need to reward the agent in a way that it is convinced that it should explore transformations. This is important as we don’t want to the agent to simply exploit around the zero distortion point. The second thing we need to take into account is that the metric we use to measure the data set distortion plays an important role. Thirdly, we need to hold into memory two copies of the data set. One copy that no distortion is applied and one copy that we distort somehow during an episode. We need this setting so that we are able to compute the column distortions. Fourthly, we need to establish the episode termination criteria i.e. when do we consider that an episode is complete. Finally, as we assume that a data set may contain strings, floating point numbers as well as integers, then computed distortions are normalized. This is needed in order to avoid having large column distortions, e.g. consider a salary column being distorted, and also being able to sum all the column distortions in a meanigful way.